2005-10-30
Mentioned on Lambda-the-Ultimate
Thanks to Lambda the Ultimate for pointing people who are interested in programming languages over to my blog. I suddenly noticed that lots of the things I talk about do not have hyperlinks to allow the interested party to find out more. Since I don't know how to go back and edit old posts, I thought I'd give a bunch of links here instead, whilst trying to be more disciplined in future.
The Haskell language.
The nhc98 compiler.
The Hat HAskell Tracer/debugger.
Failure Propagation and Transformation Calculus.
Dazzle Bayesian analysis tool.
Blobs diagram editor (webpage not yet live).
wxHaskell cross-platform GUI toolkit.
Haskell Workshop 2005.
HaXml libraries and tools.
Prerelease (1.14) of how HaXml-2 is shaping up.
DrIFT type-directed preprocessor.
Haskell Xml Toolbox from Uwe Schmidt.
The Haskell language.
The nhc98 compiler.
The Hat HAskell Tracer/debugger.
Failure Propagation and Transformation Calculus.
Dazzle Bayesian analysis tool.
Blobs diagram editor (webpage not yet live).
wxHaskell cross-platform GUI toolkit.
Haskell Workshop 2005.
HaXml libraries and tools.
Prerelease (1.14) of how HaXml-2 is shaping up.
DrIFT type-directed preprocessor.
Haskell Xml Toolbox from Uwe Schmidt.
2005-10-19
O'Caml vs Haskell - is a strict language faster?
A couple of years ago I had a student doing a project to compare Haskell with Clean for performance. He developed a translator (Hacle) from one language to the other, so the same program could be directly compared for measurement. The initial results were promising - it looked like Clean always produced faster code. But a more careful comparison over more test data showed a mixed picture, some were faster, some slower. Because the languages are so similar (both lazy) this seemed like a good test of one compiler team's skills against another.
So this year, I have a student doing something similar, only with O'Caml and Haskell. Again, there will be a translator from Haskell, and again we are looking to see if Xavier is just a better hacker than SPJ. :-) However, there is more to it this time. To what extent is laziness a time loss, or a time gain? The idea is that there are two possible translations from Haskell to O'Caml - one preserving the structure and semantics of the code, which is then simply evaluated strictly instead of lazily; and the other simulating non-strictness in O'Caml, so the code has the same termination behaviour as well as its semantics. I think everyone would expect O'Caml to win the first challenge, because of its reputation for very fast code. Even so, I suspect there may be cases where laziness is a better strategy, and Haskell might just do well. But how about lazy O'Caml vs lazy Haskell? That's the interesting question for me.
So this year, I have a student doing something similar, only with O'Caml and Haskell. Again, there will be a translator from Haskell, and again we are looking to see if Xavier is just a better hacker than SPJ. :-) However, there is more to it this time. To what extent is laziness a time loss, or a time gain? The idea is that there are two possible translations from Haskell to O'Caml - one preserving the structure and semantics of the code, which is then simply evaluated strictly instead of lazily; and the other simulating non-strictness in O'Caml, so the code has the same termination behaviour as well as its semantics. I think everyone would expect O'Caml to win the first challenge, because of its reputation for very fast code. Even so, I suspect there may be cases where laziness is a better strategy, and Haskell might just do well. But how about lazy O'Caml vs lazy Haskell? That's the interesting question for me.
2005-10-12
unifying Haskell2Xml and Xml2Haskell
So, there I was, hacking on Blobs (see below), and I realised that the file storage format for these diagrams is XML, so naturally Arjan has used the HaXml library for writing/reading these files. Great. But wait, what do I see? Even though all the internal data structures to be stored are defined in Haskell, he hasn't used the Haskell2Xml class, which can be handily derived for you by DrIFT. No, he uses the low-level generic XML parser/printer, and then hand-converts from the generic tree into and from his own data structures. Why ever did he do that? And then the first thing hit me. The Haskell2Xml methods return a "Maybe a" type. For production software, that simply isn't good enough. If the input fails to parse, then the developer is jolly well going to want an explanation of why not. The low-level generic parser gives back decent error messages if it finds a problem. But the high-level typeful parser does not. And then the second thing hit me. The Haskell2Xml method is indeed a parser. It parses the generic tree into a user-defined typeful tree. Yet it isn't written as one. Even though the low-level parser is constructed with nice combinators, Haskell2Xml doesn't use them, but rolls its own ad hoc solution.
The realisation of what I had to do was swift and immediately convincing. I had to replace HaXml's Haskell2Xml class with a true parser combinator framework. Not only that, but there is a corresponding class Xml2Haskell, derived not by DrIFT, but by the Dtd2Haskell tool, which uses an XML DTD as the source of the data structures. And yes, that too is really a parser, but was not written as one. So yes, that too needed to be rewritten.
In fact, come to think of it, why are there two classes anyway? Surely if you want to parse some XML to a typeful representation, then it is the same job, no matter where the types were originally defined. OK, so the actual instances of the class will be different depending on whether you use DrIFT or Dtd2Haskell to write them, but so what? In fact, won't there be circumstances in which you want to mix code of different origins - to dump a Haskell-derived data structure into the middle of a document with an open DTD, or vice versa? Having two separate classes would be unpleasant and unnecessary.
And thus the tale started. HaXml-2 will shortly (I hope) see the light of day. The original three kinds of parsing techniques will be reduced to one - a new set of combinators - and the parsers written with them will layer on top of one another. The generic tree parser is on the bottom, and the typeful tree parser on top, but both now using the same set of monadic combinators. It is so much more aesthetically pleasing. Not to mention giving far better error messages than before, so more practically useful too.
P.S. The Haskell Xml Toolbox from Uwe Schmidt got a new release today. Apparently it has Arrows now. Must look into that.
The realisation of what I had to do was swift and immediately convincing. I had to replace HaXml's Haskell2Xml class with a true parser combinator framework. Not only that, but there is a corresponding class Xml2Haskell, derived not by DrIFT, but by the Dtd2Haskell tool, which uses an XML DTD as the source of the data structures. And yes, that too is really a parser, but was not written as one. So yes, that too needed to be rewritten.
In fact, come to think of it, why are there two classes anyway? Surely if you want to parse some XML to a typeful representation, then it is the same job, no matter where the types were originally defined. OK, so the actual instances of the class will be different depending on whether you use DrIFT or Dtd2Haskell to write them, but so what? In fact, won't there be circumstances in which you want to mix code of different origins - to dump a Haskell-derived data structure into the middle of a document with an open DTD, or vice versa? Having two separate classes would be unpleasant and unnecessary.
And thus the tale started. HaXml-2 will shortly (I hope) see the light of day. The original three kinds of parsing techniques will be reduced to one - a new set of combinators - and the parsers written with them will layer on top of one another. The generic tree parser is on the bottom, and the typeful tree parser on top, but both now using the same set of monadic combinators. It is so much more aesthetically pleasing. Not to mention giving far better error messages than before, so more practically useful too.
P.S. The Haskell Xml Toolbox from Uwe Schmidt got a new release today. Apparently it has Arrows now. Must look into that.
2005-10-10
Completed draft 0 of interactive diagramming tool.
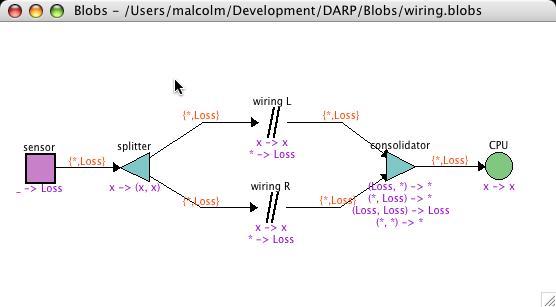
University term has just started today, so I'm feeling the potential pressure of getting snowed under with teaching commitments, so this was my last real chance to get some significant coding finished on my most recent tool project. Over the last couple of years, I've been developing the theory of FPTC - Failure Propagation and Transformation Calculus. It is a method for analysing safety-critical systems designs that consist of both software and hardware components. Essentially, you determine the failure modes of each component and communications mechanism, in response to any failures in their environment. So then you annotate each element of your design diagram with an expression denoting its failure behaviour. The calculus then allows the whole system behaviour to be determined automatically. I already had the calculus engine (written in Haskell) for some time now. But although it generated SVG diagrams as output, for input it used a textual description of the diagrams, and so was quite fiddly to use - it would take forever to layout a diagram by manually adjusting coordinates and stuff, then running the batch tool to see the result, rinse and repeat.
So, over the summer I came across Dazzle, a graphical tool for Bayesian analysis, written in Haskell using the wxWidgets toolkit. There was a paper about it at the Haskell Workshop 2005 in Tallinn. And I thought - hey, I need something just like that. Luckily, Arjan who is one of the authors is a nice chap, and although he could not release the entire source code to me, he spent an afternoon stripping Dazzle down to just the diagram editor, with no analysis backend, and sent it to me, calling it "Blobs". Fantastic! I didn't need to start a design from scratch, and didn't need to learn wxWidgets from scratch either. Just start tweaking the code and see what happens!
Well, today after only about a month's effort, I'm finally happy that Blobs, with my analysis engine plugged in, gives me the same results as I had before, with the same pretty output diagrams. But now it takes only minutes to draw a new diagram instead of hours. Click a button and the analysis is performed instantly. Very satisfying. And really, Arjan's Blobs code in Haskell was a joy to work with - totally easy to understand and modify.
Of course, this is only version 0. I still have much more in the analysis engine (tracing, probability) than I ever worked out how to display even on SVG diagrams. But these were difficult before in the batch-mode tool, mainly because of the tedious way needed to specify exactly what you wanted. It should be a lot smoother in an interactive setting.
2005-10-07
A new haskell compiler
Tom Shackell told me today about his "short weekend" project - he has completely reworked the backend of nhc98, and now has what amounts to the bulk of a new compiler he is provisionally calling "yhc" for York Haskell. Neil thinks he should call it THC (Tom's...) instead. :-)
The whole code generator and runtime system has been replaced. It now generates a platform-independent bytecode stored directly in a binary format, instead of encoding it into platform-specific C arrays that needed further C compilation. There are lots of great things about this. The generated code runs about 20% faster. You can copy the bytecode from one architecture to another without needing to recompile. The high-mem bug in nhc98's garbage collector is gone by default (new heap layout). The bytecodes are dynamically linked, so it should be possible to hot-swap running code a la hs-plugins. It works on 64-bit machines. The runtime system can be compiled natively on Windows with VC++, as well as the original gcc on Unix way.
All very cool. Now we just need to replace the frontend as well - get a decent type inference engine etc. Any volunteers?
The whole code generator and runtime system has been replaced. It now generates a platform-independent bytecode stored directly in a binary format, instead of encoding it into platform-specific C arrays that needed further C compilation. There are lots of great things about this. The generated code runs about 20% faster. You can copy the bytecode from one architecture to another without needing to recompile. The high-mem bug in nhc98's garbage collector is gone by default (new heap layout). The bytecodes are dynamically linked, so it should be possible to hot-swap running code a la hs-plugins. It works on 64-bit machines. The runtime system can be compiled natively on Windows with VC++, as well as the original gcc on Unix way.
All very cool. Now we just need to replace the frontend as well - get a decent type inference engine etc. Any volunteers?
![]()

